

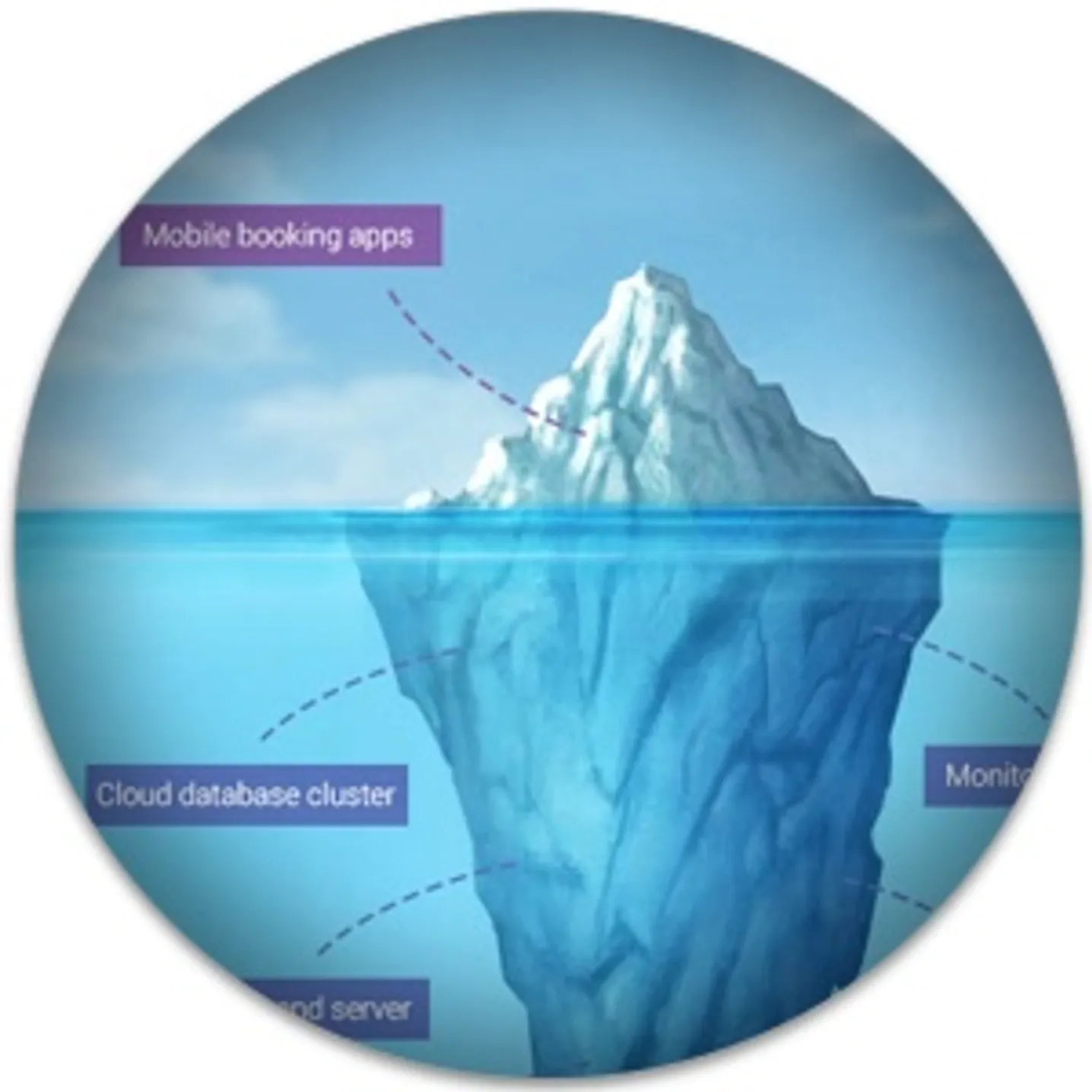
Meet the team: backend on guard of the system stability
Igor: I quit smoking. Two years ago, I promised to stop the exact moment our server would be completely stable. I thought it would happen in September 2017. Well, it’s happening now. The main services running “under the hood” of the Onde platform are Apache Cassandra, Pulsar, ZooKeeper, and our own Payments Gateway. Our server communicates with them all. The scalability of Onde solution — and, accordingly, a possibility for our clients to grow their businesses — depends on our ability to run many servers at the same time.
It creates challenges: synchronization, ensuring data integrity, and data exchange between instances. Each server instance communicates with external APIs (Google autocomplete, geocoding, OAuth, ReCaptcha, and many more). The Onde platform architecture is complex: there are cool mathematical and algorithmic solutions, a lot of integration with external and internal services, tons of business logic, an ability to process thousands of scenarios.
Over the past 1.5 years, the peak load on our server has been increased by about 40-50 times, from ≈5k per day to ≈250k orders per day. Such growth could not but affect our platform. We needed to solve many problems at an accelerated pace.
No pain, no gain: introducing RxJava 2
Artem: Our priority was enabling every single server instance to handle many more client operations than it did before. To do this, we basically rewrote the server using Reactive programming – one of the most advanced concepts existing now — RxJava 2.

Long story short, we went to bed late, got up early, worked on weekends and holidays, learned, experimented, brainstormed, got our servers up and put them back down — and got them up again! Igor: Explained in human terms, it’s a lot like having a hundred children. You need to go for a walk with them and get them dressed. You can dress them one-by-one: socks, pants, and so on. Each one of them needs to pee, as well, so you need to bring them to the bathroom, one at a time. This takes long. This is how our server handled clients’ operations before. With RxJava 2, we’ve got a possibility to dress up all the children simultaneously, — it’s faster and more efficient, no child (or order) needs to wait. The children can pee at the same time now, too.
In fact, we used a resembling technology before, even when RxJava 2 didn’t exist yet. It turns out we’ve almost created RxJava 2 from scratch — but luckily enough, somebody else did it for us. 😂 This tool gave us even more than we could expect . So right now we’re in the avant-garde of the technology. However, Reactive programming with RxJava 2 requires a lot of learning: it takes six months at least to learn its ins and outs. We’re still migrating our server to it. Already now we see our server being able to get the children dressed way more quickly and efficiently.
Every operation visualized: context really matters

Artem: We’ve created a system for monitoring the application status and visualizing the state of the system using Grafana. Workload, dynamics, changes resulting from the introduction of any new indicators — all these statistics of our server’s life was previously gathered in the form of numbers. Since we saw the numbers, not the graphics, it was difficult to see the changes and trends. We’ve created instruments on the server to collect all the necessary metrics, and now we can visualize any indicator.
Igor: When someone creates an order, about 40 operations go through the server: a lot of conditions must be met, for example, so that the same command won’t go through two times, check how much money there is on the driver’s account, check the access rights of the order creator, send a geocoding request to Google and wait for Google to pee and send you a response.
So we want to know how each operation works. Now we can track each process and see where the speed goes down. For example, how long it takes Google to pee or how quickly the drivers are being blocked for an operation. In some cases, the blocking may go slowly — but it’s unacceptable during the order creation. Until we saw all the processes separately, we couldn’t understand where the problems occurred. Now we’re tracing each particular indicator and can improve the system performance on them. The server really livens up from our efforts.
Artem: The context of operations matters a lot — and now we know it. There are at least a hundred different graphs in Grafana showing us the context.
To be continued...
Like the article? Share it with your friends!
Related posts
-
 The more our clients grow, the more challenging it becomes for Onde system stability. Our backend team is working hard to improve this and give our ride-hailing platform the power of giants. Meet the people behind the latest system enhancements and learn about the solutions they’ve implemented.
The more our clients grow, the more challenging it becomes for Onde system stability. Our backend team is working hard to improve this and give our ride-hailing platform the power of giants. Meet the people behind the latest system enhancements and learn about the solutions they’ve implemented.Backend development in simple terms. Part 2
-
 Heard of our company analytics yet? It gives your business all the data for better performance. You can always look up statistics that matter. This article explains how to get the most out of it.
Heard of our company analytics yet? It gives your business all the data for better performance. You can always look up statistics that matter. This article explains how to get the most out of it.New analytics My hub
-
 The landscape of the taxi industry is changing rapidly. Back in the days, the hardware inside cabs was a nightmare. With a pair of manufacturers cornering the market, the terminals were bulky, difficult to install and maintain. When one of the terminals crashed, which happened frequently, the entire cab had to be temporarily taken off the road
The landscape of the taxi industry is changing rapidly. Back in the days, the hardware inside cabs was a nightmare. With a pair of manufacturers cornering the market, the terminals were bulky, difficult to install and maintain. When one of the terminals crashed, which happened frequently, the entire cab had to be temporarily taken off the roadWhy you need a mobile application for drivers